上一篇,我们介绍了一部分索引的知识,本篇,我们开始介绍有关索引的其余概念。
复合索引
|
| type | possible_keys | key | rows |
|---|---|---|---|
| ref | idx_state,idx_point | idx_state | 112 |
我们发现 key 只是用了一个索引,如果 state = ‘CA’ 的结果仍然有很多的话,那么执行效率依旧很慢。
我们对 state 和 points 建立复合索引:
|
我们再次执行查询操作:
|
| type | possible_keys | key | rows |
|---|---|---|---|
| ref | idx_state,idx_point,idx_state_point | idx_state_point | 58 |
我们根据所扫描的行数可以看出,效率提高。在 MySQL 中,复合索引最多包含 16 列。
现在我们可以删除单独的 state 和 point 索引了:
|
复合索引的列顺序
我们来查看一下现在 customers 表索引情况:
|
| Key_name | Seq_in_index | Column_name | Index_type |
|---|---|---|---|
| PRIMARY | 1 | customer_id | BTREE |
| idx_lastname | 1 | last_name | BTREE |
| idx_state_point | 1 | state | BTREE |
| idx_state_point | 2 | points | BTREE |
创建复合索引时,列的顺序按照两个原则:
- 将最常用的列放在前面
- 将高唯一性的列放在前面
当索引被忽略
有时,我们存在索引,但是还是有性能问题:
|
| type | possible_keys | key | rows |
|---|---|---|---|
| index | idx_state_point | idx_state_point | 1010 |
我们发现 rows 为 1010,type 为 index,即这是一个全索引扫描,他比全表扫描快,因为没有读取记录的详细内容。尽管如此,我们还是扫描了 1010 条记录。
如何优化呢?我们可以使用之前学过的 UNION 将一个查询拆分成小查询:
|
第一个查询可以使用 idx_state_point 复合索引,第二个查询,我们新建一个索引 idx_point,来优化该查询。
我们再看一个例子:
|
这个查询仍然是全索引扫描,我们如何优化呢?
|
如果想让索引更好的工作,我们不要对列进行运算。
使用索引排序
前面我们都是使用索引进行数据筛选,我们也可以利用索引进行排序。默认情况索引排序好了:
|
我们可以看到使用索引进行排序和使用非索引列进行排序的消耗差别非常大。
如果我们使用 a, b 作为复合索引,那么以:
- a
- a, b
- a DESC, b DESC
进行排序都会直接使用索引排序,如果以:
- b
- a DESC, b
- a, b DESC
- a, c, b
进行排序,除了使用索引排序还会使用 filesort,消耗非常大。有一个情况例外,如果有 a 条件,那么以 b 进行排序,还是直接只使用索引排序。
|
我们如果看明白下图,本节内容也就明白了。注意我是把 BTREE 转化为列表方便理解记忆。

覆盖索引
如果我们的查询只使用索引,而不用触碰表就可以完成,就称为覆盖索引。
覆盖索引的条件是,所选字段是索引以及从属索引。
我们可以看看是否可以将 WHERE 子句包含进索引,再看看 ORDER BY 子句是否可以包含进索引,最后看 SELECT 子句是否可以包含进索引。
索引维护
索引可以显著提升查询效率,但是有优点就会有缺点,我们需要注意处理无用和重复索引。
MySQL 不会阻止我们生成重复索引,所以我们在新建索引之前要检查是否已经存在该索引。
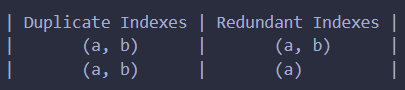
要注意: 如果有 (a,b) 索引,(b,a) 和 b 索引都不是无用索引。
必须注意: 我们在新建索引之前,一定要检查,是不是可以扩展现有索引。